Die Psychoakustik beschreibt und erklärt die Zusammenhänge zwischen den physikalisch meßbaren akustischen Reizen (z.B. Intensität, Frequenz, Dauer) und den dadurch beim Menschen ausgelösten Empfindungen (z.B. Lautheit, Empfindungstonhöhe, subjektive Dauer). Psychoakustische Erkenntnisse und Modelle, welche für das Verständnis von modernen Audiocodierverfahren (z.B. MP3, DCC und MiniDisc) und von aktuellen Sprachqualitätsmaßen (z.b. PSQM) notwendig sind, werden in der Folge vorgestellt.
Psychoakustische Grundlagen - Weiterer Inhalt:
Wichtige Ergebnisse der Psychoakustik werden unter dem Begriff der Verdeckung oder auch Maskierung zusammengefaßt. Ein Nutzschall (z.B. menschliche Sprache) kann durch einen Störschall (z.B. startendes Flugzeug) völlig verdeckt und damit unhörbar werden. Erst bei einer signifikanten Erhöhung des Pegels des Nutzschalls kann dieser vor dem Hintergrund des Störschalls wieder wahrgenommen werden. Ein noch nicht völlig verdeckter Nutzschall kann darüber hinaus durch einen Störschall in seiner Lautheitsempfindung vermindert werden. Hier spricht man dann von 'Drosselung der Lautheit'. Bei nichtsimultaner Darbietung von Nutz- und Störschall treten zeitliche Effekte wie Vor- und Nachverdeckung auf. So kann z.B. ein Nutzschall, welcher kurze Zeit nach einem Störschall auftritt, eine gewisse Zeit lang entweder völlig verdeckt oder in seiner Lautheitsempfindung gedrosselt werden.
Zur quantitativen Fassung dieser Phänomene wurden von Zwicker die sogenannten Mithörschwellen gemessen [Zwicker82]. Als Nutzschall (Testton) fungiert hier meistens ein Sinuston, welcher durch einen weiteren Sinuston, Tonkomplex oder ein Rauschsignal (Schmalbandrauschen, Bandpaßrauschen, Hoch- und Tiefpaßrauschen, gleichmäßig anregendes oder verdeckendes Rauschen) gestört wird. Als Mithörschwelle definiert man nun den Pegel des Nutzschalls, welchen dieser haben muß, um neben dem Störschall gerade noch mitgehört werden zu können. Variiert man den Testton in der Frequenz (sinnvoll ist hier der vom menschlichen Gehör wahrnehmbare Bereich von 20 Hz bis 20 kHz) und zeichnet die gemessenen Mithörschwellen in ein Diagramm ein, ergibt sich eine Darstellung der Mithörschwelle in Abhängigkeit von der Testtonfrequenz als Kurve. Variiert man als weiteren Parameter noch den Schalldruckpegel des Störschalls, so ergeben sich Kurvenscharen, welche das Phänomen 'Verdeckung' in graphischer Form darstellen. Abbildung 1 zeigt ein Beispiel.
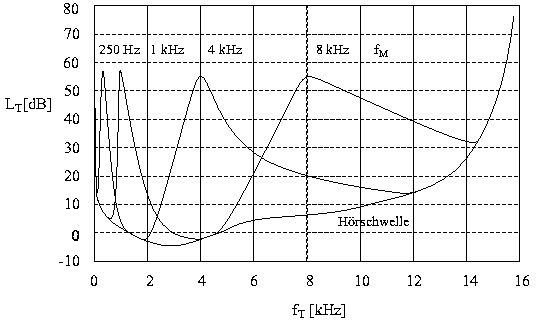
Abbildung 1: Verdeckung eines Sinustons durch frequenzgruppenbreites Schmalbandrauschen (D fG =100 Hz, 160 Hz, 700 Hz und 1700 Hz) mit unterschiedlichen Mittenfrequenzen fM = 250 Hz, 1 kHz, 4 kHz und 8 kHz und einem Schalldruckpegel von 60 dB. Die Frequenzachse ist linear skaliert. LT ist der Pegel, den ein reiner Ton haben muß, um bei der entsprechenden Frequenz gerade mitgehört zu werden. Die für die Pegelberechnung verwendete Bezugsschallintensität I0 besitzt den Wert 10-12 Watt / m2 .
Die Mithörschwellen sind aus verschiedenen Gründen von Interesse. Eine direkte Anwendung ergibt sich in der Codierung von Sprach- bzw. Audiosignalen: Ein zu codierender Signalabschnitt bewirkt eine Mithörschwelle. Zusätzliche Signale, also auch die durch die Datenkompression bedingten unvermeidbaren Fehler, bleiben unhörbar, sofern ihre spektralen Anteile die Mithörschwelle nicht erreichen. Ein Codierverfahren sollte also dafür sorgen, daß die Codierfehler unterhalb der Mithörschwelle des uncodierten Signals bleiben. So können beispielsweise Filterbankcodierverfahren die Bitratenzuteilungen in den einzelnen Teilbändern so steuern, daß die Quantisierungsfehler in den Teilbändern die Mithörschwelle nicht erreichen. Umgekehrt könnte ein instrumentelles Verfahren zur Beurteilung der Codierungsqualität die Mithörschwellen des uncodierten Signals ermitteln und prüfen, ob und in welchem Maße der Codierungsfehler die Mithörschwelle überschreitet.
Mithörschwellen sind aber auch geeignete Hilfsmittel, wenn auf die interne Signalrepräsentation eines Schallereignisses im Gehörs geschlossen werden soll. Zwischen dem Spektrum eines Schalls und den gemessenen Mithörschwellen bestehen sehr enge Beziehungen. Dieses deutet darauf hin, daß das Gehör von dem verdeckenden Schall in einer typischen Art und Weise erregt wird, und motiviert die Einführung einer fiktiven Größe mit der Bezeichnung 'Erregung'. Die Erregung ist eine Funktion der Frequenz und kann mit einem zusätzlichen Sinuston wie mit einer Sonde abgetastet werden: Um bei einem gleichzeitig dargebotenen Maskierer hörbar zu werden, muß der als Sonde fungierende Testton irgendwo im hörbaren Frequenzbereich die durch den Maskierer verursachte und zu bestimmende Erregung signifikant ändern. Dieses wird mit steigendem Testtonpegel zuerst bei der Testtonfrequenz selbst geschehen, da hier ein Maximum an zusätzlicher Erregung auftritt. Je höher die Mithörschwelle des Testtons ist, um so größer muß also die durch den Maskierer verursachte Erregung bei der Testtonfrequenz sein. Setzt man voraus, daß für die Wahrnehmbarkeit des Testtons bei allen Testtonfrequenzen fT immer das gleiche Schwellenkriterium maßgebend ist, dann muß die für einen maskierenden Schall ermittelte Mithörschwelle als Funktion der Frequenz ein exaktes Abbild der von diesem Schall im Gehör verursachten Erregung sein. Man kann daher durch ein einfaches Verschieben einer gemessenen Mithörschwelle um wenige Dezibel nach oben auf die zugehörige Erregungsfunktion schließen.
Die Erregung besitzt wie die Mithörschwellen die physikalische Einheit einer Leistung bzw. einer Intensität. Üblicherweise werden Erregungspegel angegeben. Für eine korrekte Bestimmung der Erregung muß allerdings noch das Übertragungsverhalten von Außen- und Mittelohr berücksichtigt werden (vergleiche Artikel 'Physiologie des Gehör'). Der Transport der Schallwellen vom äußeren Schallfeld zum Innenohr hin kann gut durch ein lineares zeitinvariantes Filter modelliert werden. Den gemessenen Frequenzgang für das ebene bzw. diffuse Schallfeld zeigt Abbildung 2.
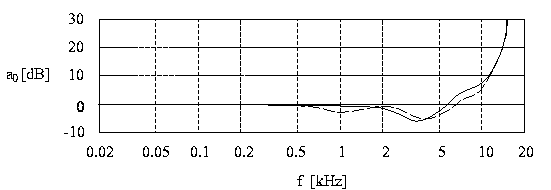
Abbildung 2: Durch Außen- und Mittelohr verursachte Dämpfung der Schallwellen für das ebene (durchgezeichnet) und das diffuse (gestrichelt) Schallfeld.
Für instrumentelle Qualitätsmaße sind gerade diese internen Repräsentationen wie die Erregung und die daraus abgeleitete Größe 'Spezifische Lautheit' von besonderem Interesse, da ein Vergleich (und eine Wertung der Unterschiede zur Berechnung eines Maßes) von uncodiertem und codiertem Signal auf dieser gehörinternen Ebene erheblich aussagekräftiger sein sollte als beispielsweise wie beim SNR ein einfacher Vergleich der Signale im Zeitbereich. Wir benötigen also Kenntnisse über die Bildung von Mithörschwellen (und damit der Erregung im Gehör) und Modelle, die es uns erlauben, die zu einem beliebigen Schallsignal gehörenden Mithörschwellen zu berechnen. Die für die Bildung von Mithörschwellen wichtigsten Mechanismen werden in den nächsten Abschnitten behandelt.
Schalle, welche ihre spektralen Eigenschaften nicht ändern und länger als 200 ms andauern, werden vom menschlichen Gehör als stationäre Vorgänge betrachtet. Unterhalb dieser Grenze ist ein Einfluß der Zeitstruktur beobachtbar. Sprache mit Stationaritätsintervallen von nur etwa 20 ms kann daher nicht als quasistationärer Vorgang behandelt werden. Dennoch lassen sich mit stationären Schallen Erkenntnisse über den menschlichen Hörvorgang gewinnen, welche auch für nichtstationäre Schalle wie Sprache anwendbar sind.
Benutzt man Bandpaßrauschen mit konstantem Schallintensitätsdichtepegel LR, aber unterschiedlicher Bandbreite Df als Maskierer, so ergeben sich die in der folgenden Abbildung 3 dargestellten Mithörschwellen [Maiwald67]. Die untere Begrenzung gibt den Verlauf der sogenannten Ruhehörschwelle wieder, welche dann Gültigkeit besitzt, wenn überhaupt kein Störschall bzw. Maskierer vorliegt. Modellhaft kann auch die Ruhehörschwelle als eine Mithörschwelle betrachtet werden, welche vom Eigenrauschen der Versuchsperson erzeugt wird. Dieses Eigenrauschen entsteht bei tiefen Frequenzen durch Puls- und Muskelbewegungen im Körper. Bei hohen Frequenzen vermutet man die Ursache innerhalb der neuronalen Verarbeitung der akustischen Reize.
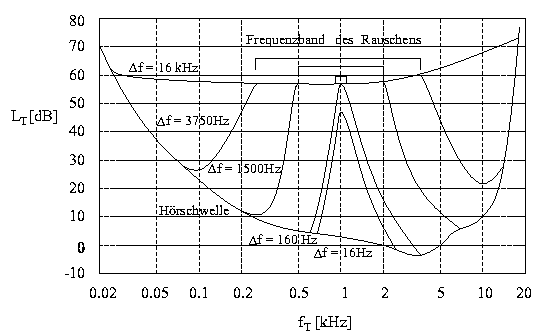
Abbildung 3: Mithörschwellen bei maskierendem Bandpaßrauschen mit konstantem Schallintensitätsdichtepegel LR=40 dB und konstanter Mittenfrequenz fM = 1 kHz, aber unterschiedlicher Bandbreite D f = 16 kHz, 3750 Hz, 1500 Hz, 160 Hz und 16 Hz.
Im Frequenzband des Rauschen ergibt sich eine konstante Mithörschwelle LT. Außerhalb dieses Bereichs jedoch zeigen die Flanken der Mithörschwellen einen verhältnismäßig flachen Abfall, obwohl das Leistungsdichtespektrum des Bandpaßrauschens eine fast ideale Rechteckform besitzt. Die Knickpunkte der Mithörschwelle stimmen recht gut mit den Bandgrenzen des Rauschens überein. Bei einer Bandbreiteneinengung des maskierenden Rauschens (hierdurch verkleinert sich die Leistung des Rauschens, da der Schallintensitätsdichtepegel konstant gehalten wird) ändert die Mithörschwelle im Frequenzband des Rauschens ihren Wert nicht, allerdings rücken die Flanken entsprechend der Bandbreite des Rauschens enger zusammen. Wird jedoch eine kritische Bandbreite DfFG unterschritten, so geht die bisher trapezförmige Gestalt der Mithörschwelle in eine eher dreieckförmige Gestalt über. Die Spitze des Dreiecks liegt bei der Mittenfrequenz fM des Rauschens. Verringert man die Bandbreite weiter, dann sinkt von nun an die Mithörschwelle für die Frequenz fT=fM unter das bisherige Niveau der Mithörschwelle. Für andere Mittenfrequenzen fM ergeben sich analoge Ergebnisse, allerdings ändert sich mit der Mittenfrequenz auch die kritische Bandbreite DfFG. Dieses Verhalten der Mithörschwellen zeigt, daß im Gehör Schallintensitäten innerhalb von kritischen Bandbreiten zusammengefaßt und diese zusammengefaßten Intensitäten zur Bildung der Mithörschwellen herangezogen werden. Die kritischen Bandbreiten werden als Frequenzgruppen bezeichnet. Zu jeder Frequenz f im Hörbereich läßt sich eine zugehörige Frequenzgruppe DfFG(f) angeben, wobei ein nichtlinearer, aber monotoner Zusammenhang zwischen f und DfFG besteht.
Als Schmalbandrauschen wird ein Rauschen bezeichnet, dessen Bandbreite kleiner als die Breite der entsprechenden Frequenzgruppe ist. In der oben schon als Beispiel angeführten Abbildung 1 werden die Maskierungskurven für vier Mittenfrequenzen dargestellt. Die Schallintensitätspegel wurden konstant gehalten (LM = 60 dB). Bei der in diesem Bild verwendeten linearen Einteilung der Frequenzachse gleichen sich die Kurven, sofern die Mittenfrequenz eine Obergrenze von etwa 500 Hz nicht überschreitet. Weiterhin verliert das Maximum der Maskierungskurven zu höheren Frequenzen hin ein wenig an Höhe (bei niedrigen Mittenfrequenzen ist die Breite der Frequenzgruppen von etwa 100 Hz sehr klein). Ein Rauschen kleiner Bandbreite enthält vom Gehör wahrnehmbare Hüllkurvenfluktuationen, welche die Erkennung eines zusätzlichen Testtones stören. Daher sind die Mithörschwellen bei niedrigen Mittenfrequenzen des verdeckenden Schmalbandrauschens etwas angehoben .
Die folgende Abbildung 4 stellt prinzipiell denselben Sachverhalt wie Abbildung 1 dar, jedoch wurde hier die Frequenzachse logarithmisch skaliert. Nun ergeben sich für die Mittenfrequenzen 1 kHz und 4 kHz sehr ähnliche Verläufe der Maskierungskurven. Bei tiefen Frequenzen jedoch ändert sich die Form der Maskierungskurven, wie hier an den Beispielen fM=70 Hz und fM=250 Hz zu erkennen ist.
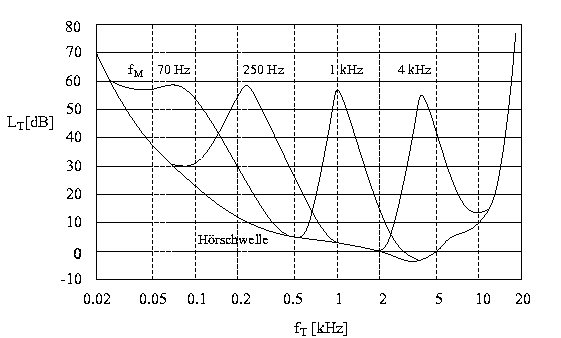
Abbildung 4: Verdeckung eines Sinustons durch frequenzgruppenbreites Schmalbandrauschen (D fG =100 Hz, 100 Hz, 160 Hz und 700 Hz) mit unterschiedlichen Mittenfrequenzen fM = 70 Hz, 250 Hz, 1 kHz und 4 kHz und einem Schalldruckpegel von 60 dB. Die Frequenzachse ist logarithmisch skaliert.
Unterhalb von 500 Hz scheint also eine lineare Skalierung der Frequenzachse zur Konstruktion der Maskierungskurven sinnvoll zu sein und oberhalb von 500 Hz eine logarithmische Einteilung. Eine Bestimmung der kritischen Bandbreiten nach dem in Abbildung 3 dargestellten Verfahren zeigt, daß die kritischen Bandbreiten ebenfalls einem solchen Gesetz unterliegen: Bis zu einer Grenzfrequenz von etwa 500 Hz haben die Frequenzgruppen eine konstante Breite von etwa 100 Hz, danach existiert ein eher logarithmischer Zusammenhang zwischen der Frequenzgruppenbreite und der Mittenfrequenz (die Bandbreite der kritischen Bänder entspricht in etwa 20 Prozent ihrer jeweiligen Mittenfrequenz).
Der experimentell bestimmete Zusammenhang zwischen der Frequenz f und der Frequenzgruppenbreite DfFG(f) kann ausgenutzt werden, um ein nichtlineares Transformationsgesetz für die Frequenzachse in eine sogenannte Tonheitsskala zu finden. Die Tonheit erhält das Formelzeichen z und besitzt die Einheit 1 Bark. Die Abbildung z=g(f) wird so konstruiert, daß eine Differenz von einem Bark an einem Ort z0 irgendwo auf der Barkskala genau der Breite der zugehörigen Frequenzgruppe entspricht:
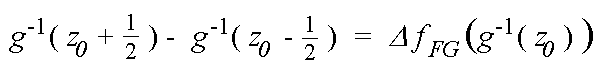
(Formel 1)
In der nachfolgenden Tabelle 1 wird eine Einteilung des hörbaren Frequenzbereichs in 24 Frequenzgruppen gezeigt. Jede Frequenzgruppe schließt hier beginnend bei 0 Hz nahtlos an die vorherige an. Frequenzen unterhalb von etwa 20 Hz sind für den Menschen nicht wahrnehmbar, dennoch wird die Abbildung von f nach z der Einfachheit halber so gewählt, daß der Punkt f=0 auf den Punkt z=0 abgebildet wird., also entspricht der hörbare Frequenzbereich auf der Tonheitsskala dem Abschnitt von 0 bis 24 Bark. Eine solche Einteilung des Frequenzbereichs findet sich in vielen Anwendungen (z.B. Audio-Codierung und Signalanalyse). Man setzt hier voraus, daß ein breitbandiges Schallereignis vom Gehör in genau diesen Teilbändern analysiert wird (Zwicker weist allerdings darauf hin, daß die Frequenzgruppen keine Vorzugslage haben, sondern sich automatisch dahin schieben, wo sie am meisten Information aufnehmen können).
| Nummer | fM [Hz] | z [Bark] | Delta fFG |
|---|---|---|---|
| 1 | 50 | 0.5 | 100 |
| 2 | 150 | 0.5 | 100 |
| 3 | 250 | 2.5 | 100 |
| 4 | 350 | 3.5 | 100 |
| 5 | 450 | 4.5 | 110 |
| 6 | 570 | 5.5 | 120 |
| 7 | 700 | 6.5 | 140 |
| 8 | 840 | 7.5 | 150 |
| 9 | 1000 | 8.5 | 160 |
| 10 | 1170 | 9.5 | 190 |
| 11 | 1370 | 10.5 | 210 |
| 12 | 1600 | 11.5 | 240 |
| 13 | 1850 | 12.5 | 280 |
| 14 | 2150 | 13.5 | 320 |
| 15 | 2500 | 14.5 | 380 |
| 16 | 2900 | 15.5 | 450 |
| 17 | 3400 | 16.5 | 550 |
| 18 | 4000 | 17.5 | 700 |
| 19 | 4800 | 18.5 | 900 |
| 20 | 5800 | 19.5 | 1100 |
| 21 | 7000 | 20.5 | 1300 |
| 22 | 8500 | 21.5 | 1800 |
| 23 | 10500 | 22.5 | 2500 |
| 24 | 13500 | 23.5 | 3500 |
Tabelle 1: Zusammenhang zwischen der Mittenfrequenz fM und der Frequenzgruppenbreite D fFG für 24 kritische Bänder. Die 24 Bänder überlappen sich nicht und decken den hörbaren Frequenzbereich vollständig ab.
In der folgenden Abbildung werden die gemessenen Maskierungskurven für Schmalbandrauschen nun mit der Tonheitsskala als Abszisse anstelle der Frequenzskala dargestellt. Alle Maskierungskurven haben jetzt im wesentlichen dieselbe Form, nur bei sehr tiefen Frequenzen verformt die Absoluthörschwelle den Mithörschwellenverlauf (dieser verformende Einfluß verschwindet bei entsprechender Pegelerhöhung bei tiefen Frequenzen). Spezielle Maskierungseffekte bei sehr tiefen Frequenzen führen außerdem dazu, daß hier die obere Flanke der Kurven etwas steiler verläuft.
Die Tonheitsskala besitzt eine fundamentale Bedeutung für die Modellierung von Gehöreigenschaften, da ein direkter Zusammenhang zum Ort auf der Basilarmembran im Innenohr besteht. Auf der Basilarmembran sind die Hörrezeptoren äquidistant angeordnet (vergleiche Artikel 'Physiologie des Gehör'). Bei der Erregung des Gehörs mit einem reinen Ton kann zwischen dem Ort des Schwingungsmaximums auf der Basilarmembran und der Tonheit z eine lineare Beziehung angegeben werden. So entspricht eine Tonheitsdifferenz von einem Bark genau einem Abschnitt von 1.3 Millimetern auf der Basilarmembran (auf einem solchen Abschnitt sind etwa 150 innere Haarzellen untergebracht). Die Einführung der Tonheitsskala kann also physiologisch motiviert werden. Mit dieser natürlichen Frequenzskala können nicht nur Maskierungseffekte einfacher beschrieben und leichter verstanden werden, sondern auch viele andere Sachverhalte und Effekte wie die Tonhöhenwahrnehmung und die gerade wahrnehmbaren Frequenzänderungen.
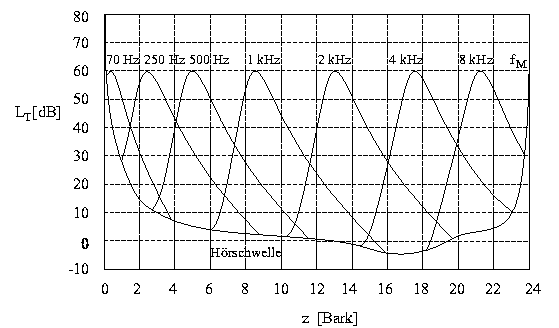
Abbildung 5: Verdeckung eines Sinustons durch frequenzgruppenbreites Schmalbandrauschen mit unterschiedlichen Mittenfrequenzen fM = 70 Hz, 250 Hz, 500 Hz, 1 kHz, 2 kHz, 4 kHz und 8 kHz und einem Schalldruckpegel von 60 dB. Die Frequenzachse wurde nichtlinear in die Barkskala transformiert.
Abbildung 6: Zusammenhang zwischen dem Ort des Schwingungsmaximums auf der Basilarmembran und der Tonheit z bei einem reinen Ton
Abbildung 7 zeigt die Maskierungskurven, welche man für ein verdeckendes Schmalbandrauschen der Mittenfrequenz 1 kHz und der Bandbreite 160 Hz bei unterschiedlichen Pegeln LM messen kann. Die Frequenzachse ist logarithmisch skaliert. Alle Kurven steigen sehr schnell an (etwa 100 dB/Oktave bzw. 27 dB/Bark ) und erreichen ein Maximum, dessen Wert etwa bei 3 dB unter dem Pegel des Schmalbandrauschens liegt. Die obere Flanke der Verdeckungskurven verläuft bei höheren Pegeln wesentlich flacher. Mit zunehmendem Pegel des Maskierers wird ihr Verlauf immer flacher, man bezeichnet diesen nichtlinearen Effekt als 'nichtlineare Auffächerung der oberen Flanke'. Bei Rauschpegeln über 80 dB ergeben sich Einsattelungen in der Mithörschwelle (gestrichelt gezeichnet), da hier aufgrund von Nichtlinearitäten im Gehör Differenztöne wahrnehmbar werden. Für die Hörbarkeit des Testtons maßgeblich sind die durchgehend gezeichneten Kurvenzüge. Man vermutet, daß die nichtlineare Auffächerung der oberen Flanke durch einen Rückkoppelmechanismus im Innenohr entsteht (vergleiche Artikel 'Physiologie des Gehör'). Bei niedrigen Pegel wird dieser über die äußeren Haarzellen vermittelte Mechanismus relevant und bewirkt eine schmalere Amplitudenverteilung der Wanderwellen und damit auch schmalere Maskierungskurven. Diese Vermutung wird durch physiologische Messungen der Schwingungsformen der Basilarmembran bei unterschiedlichen Pegeln und durch Modellrechnungen bestätigt: Die Hüllkurven entsprechen den ermittelten Maskierungskurven [Zwicker91, Fastl90]. Die Simultanverdeckung entsteht demnach schon im Innenohr vor der mechanisch-elektrischen Umwandlung in nervöse Aktionspotentiale.
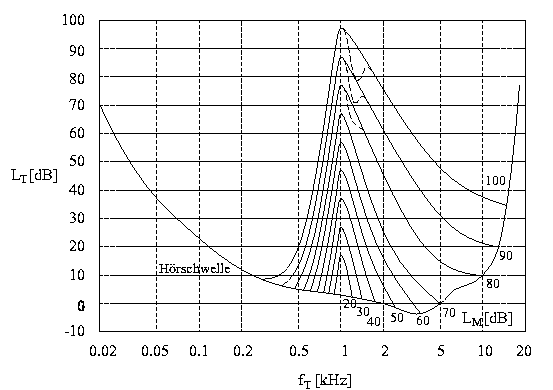
Abbildung 7: Verdeckung eines Sinustons durch frequenzgruppenbreites Schmalbandrauschen der Mittenfrequenz 1 kHz mit unterschiedlichen Pegeln LM. Der Sinuston wird hörbar, wenn sein Pegel die Mithörschwelle LT erreicht.
Man erhält sehr ähnliche Verdeckungskurven, wenn man statt eines Schmalbandrauschens einen pegelgleichen reinen Ton als Maskierer verwendet. Auch hier findet sich der der steile Anstieg der Maskierungskurven, allerdings ist hier der Anstieg pegelabhängig und bei niedrigen Pegeln weniger steil. Der flachere Abfall und die nichtlineare Auffächerung der oberen Flanke können ebenfalls beobachtet werden. Auch hier können nach einer Transformation von Frequenz nach Tonheit die Maskierungskurven im wesentlichen durch horizontale Verschiebung eines Kurvenprototyps gewonnen werden. Die Maskierungskurven für Sinustöne lassen sich allerdings wegen der auftretenden Schwebungen und Differenztöne (diese entstehen aufgrund der Nichtlinearitäten im Gehör, vergleiche Artikel 'Physiologie des Gehör') erheblich schwieriger ermitteln als die Maskierungskurven für Schmalbandrauschen. Im wesentlichen finden wir also für reine Töne dieselben Maskierungskurven wie für Schmalbandrauschen.
Die in den vorangegangenen Abschnitten dargestellten Erkenntnisse über die Bildung von Mithörschwellen ermöglichen es, für spektral beliebig geformte quasistationäre Schallereignisse die zugehörigen Erregungsfunktionen zu bestimmen. Zwicker hat hierzu ein Konstruktionsverfahren entwickelt. In der folgenden Abbildung wird die Bestimmung der Erregung E als Funktion der Tonheit z für weißes Rauschen, Schmalbandrauschen und einen Mehrtonkomplex nach diesem Verfahren dargestellt. Zunächst wird die Schallintensitätsdichte als Funktion der Frequenz angegeben. Danach wird die Frequenz f in die Tonheit z überführt. Im dritten Schritt wird für jede Tonheit z die in die zugehörige Frequenzgruppe fallende Schallintensität IG bestimmt (diese Größe wird als Anregung bezeichnet). Die Bestimmung der Anregung kann als Faltung der über der Tonheitsskala aufgetragenen Schallintensitätsdichte mit einem Rechteck der Breite 1 Bark gedeutet werden. Die Umrechnung in Pegel erfolgt im vierten Schritt. Im fünften und letzten Schritt werden die empirisch ermittelten Maskierungskurven dort angesetzt, wo sich der Anregungspegel abrupt ändert. Wie sich Erregungen, die zu verschiedenen spektralen Komponenten gehören, zu einer Gesamterregung überlagern, ist noch nicht vollständig geklärt. Näherungsweise können die Erregungen einfach addiert werden. In den meisten Fällen dominiert jedoch eine Komponente und bestimmt die Gesamterregung.
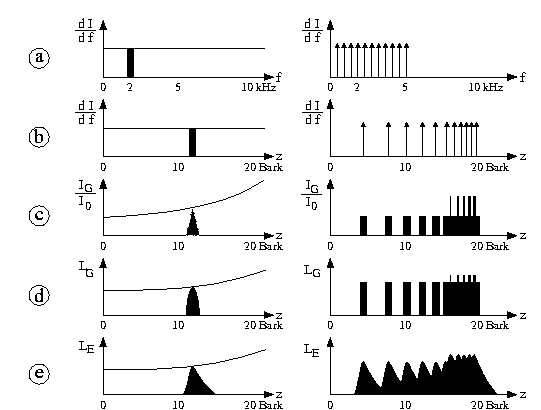
Abbildung 8: Konstruktionsverfahren nach Zwicker zur Modellierung der Erregung. Links: weißes Rauschen und Schmalbandrauschen. Rechts: Mehrtonkomplex. (a): Intensitätsdichte als Funktion der Frequenz. (b): Intensitätsdichte als Funktion der Tonheit. (c): In die jeweilige Frequenzgruppe fallende Intensität (Anregung). (d): Anregungspegel. (e): Erregungspegel (Berücksichtigung der Maskierungskurven).
Die Lautheit eines Schalls ist eine seiner wesentlichen Kenngrößen.
Die Lautheitsempfindung eines Schalls hängt nicht nur von der Schallintensität, sondern auch von der spektralen Zusammensetzung des Schalls ab. So wird ein breitbandiges Rauschen als wesentlich lauter empfunden als ein pegelgleicher reiner Ton. Üblicherweise wird die Lautheitsempfindung eines beliebigen Schallereignisses beschrieben durch den sogenannten Lautstärkepegel. Der Lautstärkepegel L1 kHz ist definiert als der Schalldruckpegel eines reinen 1-kHz-Tones, welcher dieselbe Lautheitsempfindung hervorruft wie der zu messende Schall. Die Einheit des Lautstärkepegels ist 1 Phon. Einen direkten Vergleich der Lautheitsempfindung zweier Schallereignisse gestattet die Größe Lautheit, welche das Formelzeichen N und die Einheit 1 Sone besitzt. Ein beliebiger Schall mit der Lautheit 2 Sone wird demnach als doppelt so laut empfunden wie ein zweiter beliebiger Schall mit der Lautheit 1 Sone. Die Lautheit eines 1-kHz-Tones mit einem Pegel von 40 dB wird hierbei als 1 Sone definiert.
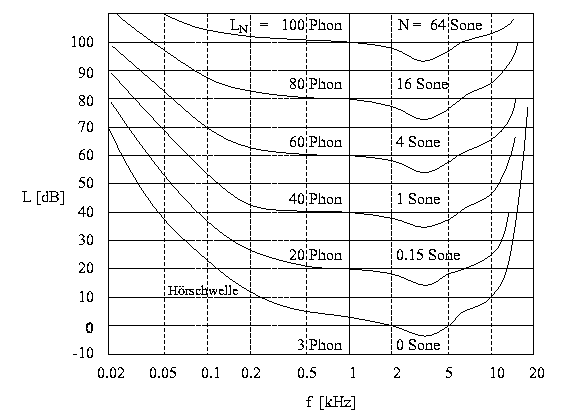
Abbildung 9: Kurven gleicher Lautheit für reine Töne im ebenen Schallfeld.
In der obigen Abbildung 9 werden die Kurven gleicher Lautheit für Sinustöne unterschiedlicher Frequenz dargestellt. Bei höheren Pegel (L>40dB) verdoppelt sich die Lautheit eines 1-kHz-Tones bei einer Pegelerhöhung um 10 dB, also bei einer Verzehnfachung der Schallintensität. Schallintensität und Lautheit eines 1-kHz-Tones sind demnach für höhere Pegel über ein Potenzgesetz mit dem Exponenten 0.3 verknüpft:
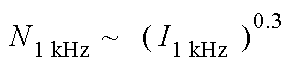
(Formel 2)
Die Lautheitsempfindung wird ausgelöst durch eine Erregung der Hörrezeptoren im Cortischen Organ auf der Basilarmembran (vergleiche Artikel 'Physiologie des Gehör'). Eine sinnvolle Annahme besteht darin, daß die Erregung eines jeden Hörrezeptors gleich wichtig für die empfundene Lautheit ist. Jeder Hörrezeptor sollte entsprechend seiner Erregung mit einer Teillautheit zu der Gesamtempfindung Lautheit beitragen, welche sich schließlich als einfache Summe der Teillautheiten ergibt. In den vorangegangenen Abschnitten wurden schon die aus den gemessenen Maskierungskurven ableitbaren Gesetzmäßigkeiten zur Bildung der Erregung im Gehör erörtert. Diese Erregung sollte über ein noch zu findendes Gesetz verknüpft sein mit den gesuchten Teillautheiten. Bei der Modellierung der Erregung wird allerdings abgesehen von der diskreten Natur der Hörrezeptoren, und die Erregung wird als eine kontinuierliche Größe (sinnvollerweise über der Tonheitsskala, da hier die Dichte der Hörrezeptoren konstant ist) betrachtet. Die Teillautheiten gehen demnach über in eine kontinuierliche Lautheitsdichte, welche den Namen Spezifische Lautheit und das Formelzeichen N' erhält. Das Integral über diese Lautheitsdichte mit der Einheit 1 Sone/Bark ersetzt die Summe von Teillautheiten und modelliert die Gesamtempfindung Lautheit:
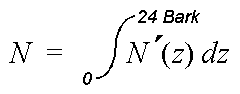
(Formel 3)
Für die Bestimmung des gesuchten Zusammenhangs zwischen der Erregung und der Spezifischen Lautheit ist ein reiner Ton weniger gut geeignet, da er ein kompliziertes und pegelabhängiges Erregungsbild bewirkt. Einfacher werden die Verhältnisse, wenn man ein spezielles Rauschen verwendet, welches eine konstante Erregung hervorruft. Ein solches Rauschen wird als Gleichmäßig Anregendes Rauschen bezeichnet [Zwicker82]. Auch hier findet man für höhere Pegel ein Potenzgesetz, jedoch mit dem Exponenten 0.23:
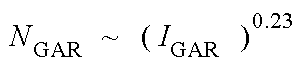
(Formel 4)
Da dieses Rauschen eine konstante Erregung (pro Bark) und demnach auch eine konstante Spezifische Lautheit erzeugt, muß für höhere Pegel also gelten:
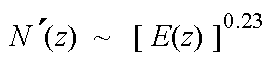
(Formel 5)
Eine Berücksichtigung der Verhältnisse in der Nähe der Hörschwelle und eine passende Normierung (ein 1 kHz-Ton mit einem Pegel von 40 dB muß eine Lautheit von 1 Sone bewirken) liefern schließlich den gesuchten Zusammenhang zwischen der Erregung und der Spezifischen Lautheit:
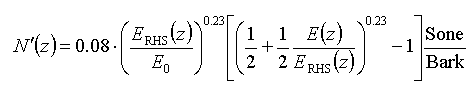
(Formel 6)
ERHS bezeichnet die Erregung an der Ruhehörschwelle, und E0 ist die Erregung, welche dem Normierungsfaktor I0 für die Intensität entspricht.
Die Lautheit eines beliebigen quasistationären Schallereignisses kann somit geschätzt werden: Zunächst wird die Erregungsfunktion z.B. mit dem oben dargestellten Verfahren von Zwicker bestimmt, danach wird die Erregung mit Formel 6 in die Spezifische Lautheit überführt, deren Integral schließlich eine Schätzung für die Lautheit liefert. Mit einer solchen Methode kann in der Tat die subjektiv empfundene Lautheit eines Schalls sehr genau geschätzt werden. Daher wurde in DIN 45631 bzw. ISO R 532 B ein entsprechendes Verfahren zur Lautheitsschätzung genormt. Programme zur Berechnung der Lautheit wurden ebenfalls veröffentlicht [Paulus72]. Dort wird allerdings die Erregung nicht explizit ausgerechnet, sondern es wird direkt die Spezifische Lautheit aus Frequenzgruppen- bzw. (nach einer Korrektur) aus Terzpegeln bestimmt.
Ein Ton muß eine gewisse Dauer haben, um überhaupt als solcher erkannt zu werden. Diese Mindestdauer beträgt ungefähr 10 bis 15 ms. Unterhalb dieser Länge wird der Schall nicht als Ton, sondern als Klicken wahrgenommen. Tönen, die länger als 10 bis 15 ms wirken, kann eine eindeutige Tonhöhe und subjektive Lautheit zugeordnet werden. Diese subjektive Lautheitsempfindung hängt im Gegensatz zur Tonhöhenempfindung von der Länge des dargebotenen Tones ab. Erst ab einer Tondauer von etwa 200 ms wird die Lautstärke als unabhängig von der Tondauer empfunden.
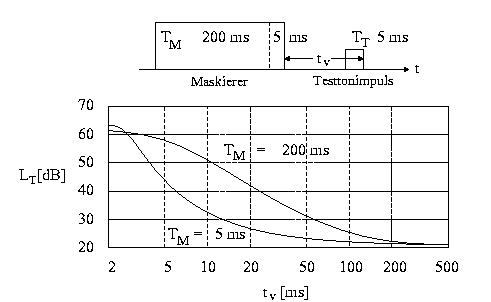
Abbildung 10: Abhängigkeit der Nachverdeckung von der Dauer TM (mindestens 200 ms bzw. 5ms) des maskiererenden Schalls (hier: Gleichmäßig Maskierendes Rauschen). Der 2 kHz-Testtonimpuls kann zur Zeit tv nach Ende des Maskierers wahrgenommen werden, wenn sein Pegel LT mindestens die Mithörschwelle erreicht.
Bei den zeitabhängigen Verdeckungseffekten unterscheidet man die drei Bereiche Vorverdeckung, Simultanverdeckung und Nachverdeckung.Vorverdeckung findet in einem Bereich vor Einsetzen des Maskierers statt. Das Gehör arbeitet in diesem Bereich natürlich nicht nichtkausal, sondern verarbeit laute Schalle schneller als leise. Die endliche Verarbeitungszeit des Gehörs kann also bewirken, daß laute Schalle sozusagen leise Schalle während der Verarbeitung überholen, obwohl physikalisch die leisen Schalle vor den lauten eingesetzt haben. Die Vorverdeckung wird in einem Bereich von ungefähr 20 ms vor Einsetzen des verdeckenden Schalls wirksam. Nach der Vorverdeckung folgt die Simultanverdeckung, wo Maskierer und Testschall gleichzeitig vorliegen. Bei einer zeitlichen Dauer des Nutzschalls von weniger als etwa 200 ms unterscheiden sich die entstehenden Mithörschwellen von den Mithörschwellen bei Dauerschall. In diesem Fall ist eine Anhebung der Mithörschwellen zu beobachten, was mit der verminderten subjektiven Lautstärke von Tönen einer Dauer unterhalb von 200 ms in Einklang steht. Nach Abschalten des Maskierers wird die Nachverdeckung wirksam, welche als eine kurzzeitige Vertaubung des Gehörs interpretiert werden kann. Hier verdeckt also der Maskierer noch ganz oder teilweise den Testschall, obwohl der Maskierer physikalisch gar nicht mehr vorhanden ist. Die Nachverdeckung wirkt sich über 100 ms aus und bildet damit den dominierenden Effekt bei den von der Zeitstruktur des Schalls abhängigen Verdeckungseffekten.
Die Nachverdeckung hängt von der zeitlichen Dauer TM des maskiererenden Schalls ab. In Abbildung 11 wird als Beispiel die Mithörschwelle für einen 2 kHz-Testtonimpuls von 5 ms Dauer gezeigt, welcher nach einer Zeit tv nach Ende eines maskierenden Schalls dargeboten wird (hierbei wird Gleichmäßig Maskierendes Rauschen als Maskierer gewählt). Die Dauer des maskierenden Rauschens beträgt 200 ms bzw. 5 ms. Ausgehend vom Wert für die Simultanverdeckung klingt die Mithörschwelle bei der Nachverdeckung als Funktion der Verzögerungszeit tv ab. Die Kurve für eine Maskiererdauer von 5 ms fällt erheblich schneller als die Kurve für 200 ms, welche eine Grenzkurve darstellt und auch für länger andauernde Maskierer gilt.
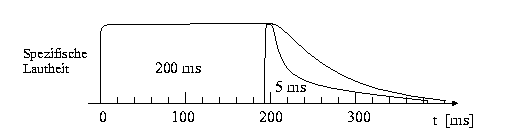
Abbildung 11: Spezifische Lautheit (für einen Punkt z0 auf der Tonheitsskala), welche von Maskierern der Länge 200 ms bzw. 5 ms erzeugt wird.
Die Zeitabhängigkeit der Mithörschwellen bedeutet eine Zeitabhängigkeit der Erregung des Gehörs und damit auch der Spezifischen Lautheit. Die gefundenen Mithörschwellen für die Simultan- und Nachverdeckung können eingesetzt werden, um auf den zeitlichen Verlauf der Spezifischen Lautheit zu schließen (die Vorverdeckung wird hierbei im allgemeinen vernachlässigt). In Abbildung 11 wird der Verlauf der spezifischen Lautheit für die zwei Maskierer aus Abbildung 10 qualitativ dargestellt. Beide Maskierer werden auf der Zeitachse so dargestellt, daß sie zum selben Zeitpunkt t=200 ms enden. Das von der Signaldauer abhängige Abklingverhalten der Spezifischen Lautheit läßt sich durch einen exponentiellen Abfall nur unzureichend modellieren. Eine genauere Modellierung gelingt z.B. mit Arcustangens-Funktionen.
Der zeitliche Verlauf der Spezifischen Lautheit für kompliziertere und zeitlich stark strukturierte Schalle kann nun ermittelt werden, indem die Erkenntnisse über die Bildung der Spezifischen Lautheit im quasistationären Fall und die Erkenntnisse über ihr Zeitverhalten im instationären Fall kombiniert werden. In einer Anwendung können beispielsweise mit einer Filterbank die (zeitabhängigen) Frequenzgruppenpegel bestimmt werden. Aus diesen Pegeln ergeben sich durch Berücksichtigung der Maskierungskurven (für die Verdeckung im Frequenzbereich) die Erregungspegel, welche mit Formel 6 in Spezifische Lautheiten umgerechnet werden können. Die Nachverdeckung als Zeitbereichseffekt sollte dann berücksichtigt werden, wenn die zuvor berechneten Spezifischen Lautheiten sehr schnell abfallen: Hier werden dann Abklingkurven wie in Abbildung 11 angesetzt, um den sanfteren Abfall der Spezifischen Lautheit zu modellieren. In Abbildung 12 wird die Spezifische Lautheit wie in einem Spektrogramm als Funktion der Zeit und der Tonheit für das Wort 'Elektroakustik' dargestellt (vgl. z.B. die entsprechende Abbildung in [Zwicker82]). Die Berechnung erfolgte mit einem automatischen Verfahren, welches ich im Rahmen meiner Forschungstätigkeit entwickelt habe.
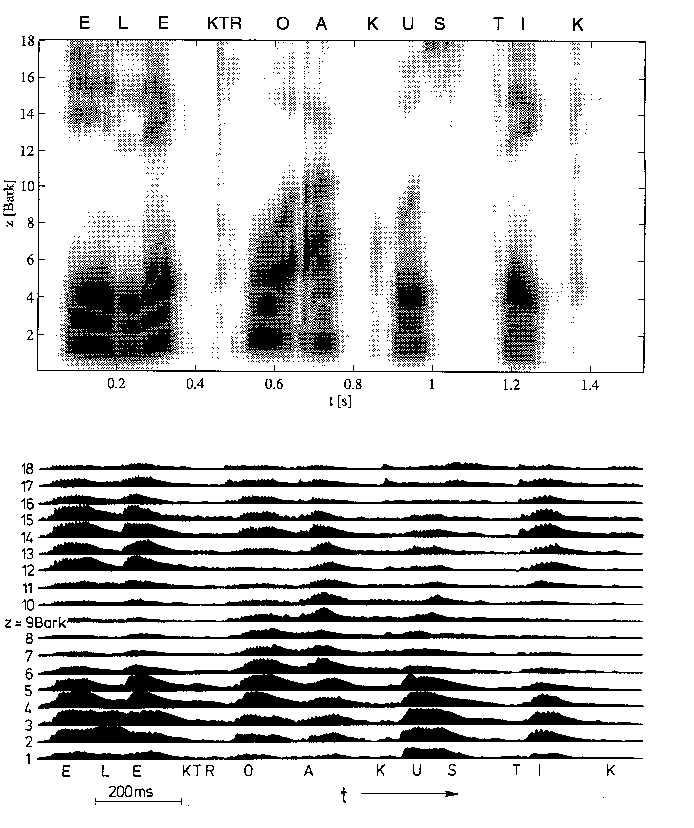
Abbildung 12: Spezifische Lautheit als Funktion der Zeit und der Tonheit für das Wort 'Elektroakustik'. Das untere Bild wurde aus [Zwicker82] entnommen. Im oberen Bild wurde die Spezifische Lautheit mit einem Programm berechnet. Dunkle (helle) Bereiche bedeuten große (kleine) spezifische Lautheiten. Es handelt sich natürlich nicht um die gleichen Sprecher, dennoch sind die Ähnlichkeiten offensichtlich.
Die Darstellung eines Schalls in einem dreidimensionalen Zeit-Tonalität-Lautheitmuster orientiert sich an der menschlichen auditiven Wahrnehmung. Instrumentelle Sprachqualitätsmaße, welche Unterschiede in den Lautheitmustern von originaler und prozessierter Sprache bewerten, sollten daher aussagekräfiger sein als einfache Maße, welche lediglich die Zeitfunktionen oder Spektren vergleichen.
[Zwicker82] Zwicker, Psychoakustik, Springer Verlag, Berlin, Heidelberg, New York, 1982.
[Fastl90] E. Zwicker and H. Fastl, Psychoacoustics - Facts and Models, Springer-Verlag Berlin Heidelberg, 1990.
[Maiwald67] D. Maiwald, Beziehungen zwischen Schallspektrum, Mithörschwelle und der Erregung des Gehörs,
Acustica, Vol.18, 1967.
[Zwicker91] E. Zwicker, U.T. Zwicker, Audio Engineering and Psychoacoustics: Matching Signals to the Final Receiver, the Human
Auditory System, J. Audio Eng. Soc., Vol. 39, No. 3, March 1991.
[Paulus72] E. Paulus, E. Zwicker, Programme zur automatischen Bestimmung der Lautheit aus Terzpegeln oder Frequenzgruppenpegeln,
Acustica, Vol.27, 1972.
[Moore96] B.C.J. Moore, B.R.Glasberg, A Revison of Zwicker's Loudness Model, ACUSTICA / acta acustica, Vol. 82 (1996)